
专刊/专栏


Frontiers of Computer Science 70周年校庆专刊

Frontiers of Computer Science 70周年校庆专刊
Oct 2022, Volume 16 Issue 5
Frontiers of Computer Science 70周年校庆专刊
The mass, fake news, and cognition security
Bin GUO, Yasan DING, Yueheng SUN, Shuai MA, Ke LI, Zhiwen YU.
doi:10.1007/s11704-020-9256-0
2021, 15(3): 153806
 摘要
摘要
The widespread fake news in social networks is posing threats to social stability, economic development, and political democracy, etc. Numerous studies have explored the effective detection approaches of online fake news, while few works study the intrinsic propagation and cognition mechanisms of fake news. Since the development of cognitive science paves a promising way for the prevention of fake news, we present a new research area called Cognition Security (CogSec), which studies the potential impacts of fake news on human cognition, ranging from misperception, untrusted knowledge acquisition, targeted opinion/attitude formation, to biased decision making, and investigates the effective ways for fake news debunking. CogSec is a multidisciplinary research field that leverages the knowledge from social science, psychology, cognition science, neuroscience, AI and computer science. We first propose related definitions to characterize CogSec and review the literature history.

GridNet: efficiently learning deep hierarchical representation for 3D point c...
Huiqun WANG, Di HUANG, Yunhong WANG.
doi:10.1007/s11704-020-9521-2
2022, 16(1): 161301
摘要
In this paper, we propose a novel and effective approach, namely GridNet, to hierarchically learn deep representation of 3D point clouds. It incorporates the ability of regular holistic description and fast data processing in a single framework, which is able to abstract powerful features progressively in an efficient way.Moreover, to capture more accurate internal geometry attributes, anchors are inferred within local neighborhoods, in contrast to the fixed or the sampled ones used in existing methods, and the learned features are thus more representative and discriminative to local point distribution. GridNet delivers very competitive results compared with the state of the art methods in both the object classification and segmentation tasks.

Revenue-maximizing online stable task assignment on taxi-dispatching platform...
Jingwei LV, Ze ZHAO, Shuzhen YAO, Weifeng LV.
doi:10.1007/s11704-021-0363-3
2022, 16(6): 166208
摘要
The main purpose of the problem is matching drivers to passengers, on the premise of a balance between price and distance, to maximize platforms’ revenue. In this letter, the baseline algorithm based on traditional solution for spatial assignment is performed. It fails to deliver satisfying results on revenue maximizing. Furthermore we propose a problem called revenue-maximizing online stable matching(RMOSM) problem with a new algorithm equation-substitutable online matching(ESOM). Compared to the baseline algorithm, the ESOM algorithm can cater to platforms' request for higher profits.
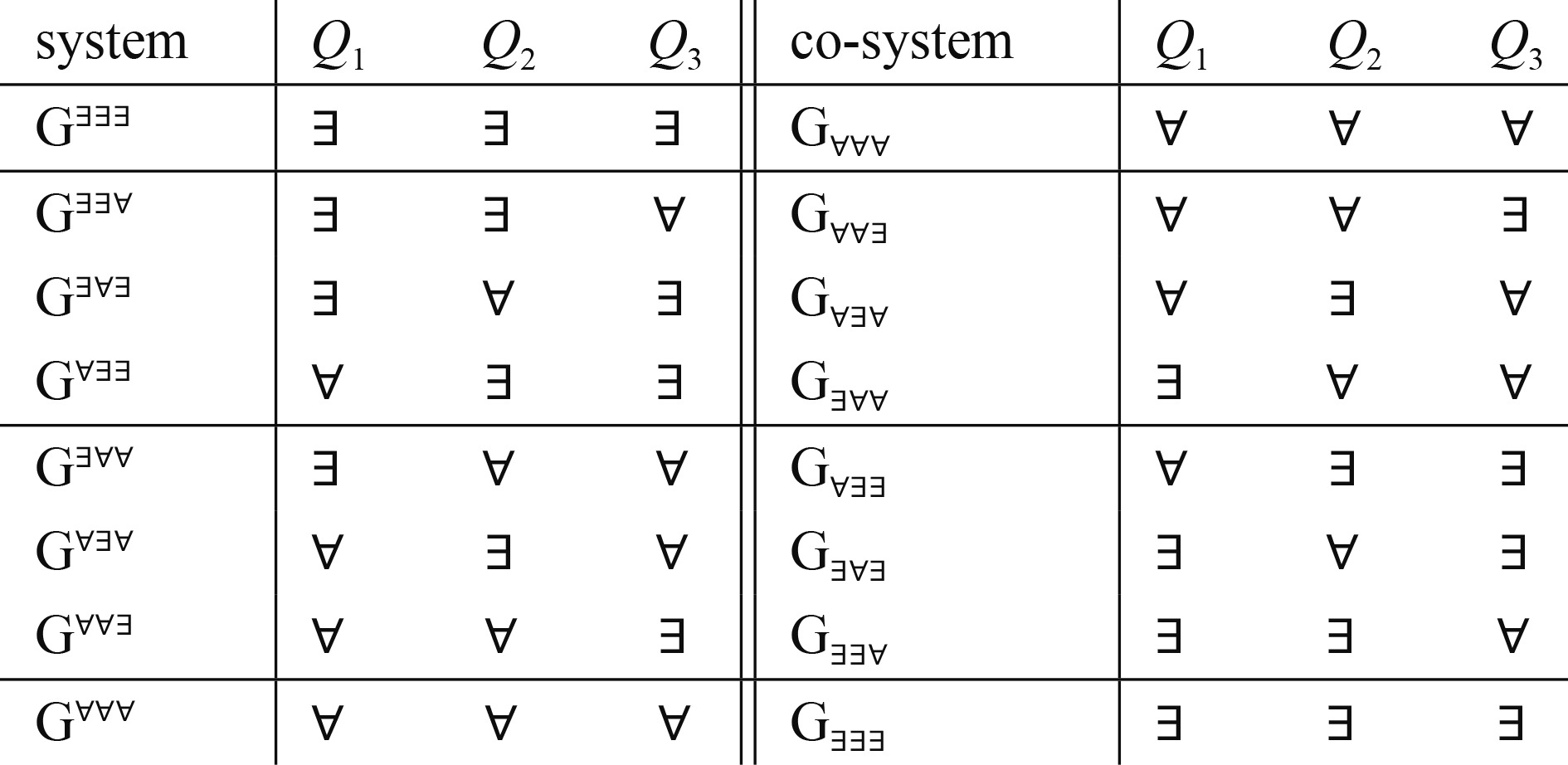
Monotonicity and nonmonotonicity in L3-valued propositional logic
Wei LI, Yuefei SUI.
doi:10.1007/s11704-021-0382-0
2022, 16(4): 164315
摘要
A sequent is a pair which is true under an assignment if either some formula in is false, or some formula in is true. In -valued propositional logic, a multisequent is a triple which is true under an assignment if either some formula in has truth-value or some formula in has truth-value or some formula in has truth-value . There is a sound, complete and monotonic Gentzen deduction system for sequents. Dually, there is a sound, complete and nonmonotonic Gentzen deduction system for co-sequents By taking different quantifiers some or every, there are 8 kinds of definitions of validity of multisequent and 8 kinds of definitions of validity of co-multisequent and correspondingly there are 8 sound and complete Gentzen deduction systems for sequents and 8 sound and complete Gentzen deduction systems for co-sequents. Correspondingly their monotonicity is discussed.

PSLDA: a novel supervised pseudo document-based topic model for short texts
Mingtao SUN, Xiaowei ZHAO, Jingjing LIN, Jian JING, Deqing WANG, Guozhu JIA.
doi:10.1007/s11704-021-0606-3
2022, 16(6): 166350
摘要
Various kinds of online social media applications such as Twitter and Weibo, have brought a huge volume of short texts. However, mining semantic topics from short texts efficiently is still a challenging problem because of the sparseness of word-occurrence and the diversity of topics. To address the above problems, we propose a novel supervised pseudo-document-based maximum entropy discrimination latent Dirichlet allocation model (PSLDA for short). Specifically, we first assume that short texts are generated from the normal size latent pseudo documents, and the topic distributions are sampled from the pseudo documents. In this way, the model will reduce the sparseness of word-occurrence and the diversity of topics because it implicitly aggregates short texts to longer and higher-level pseudo documents.
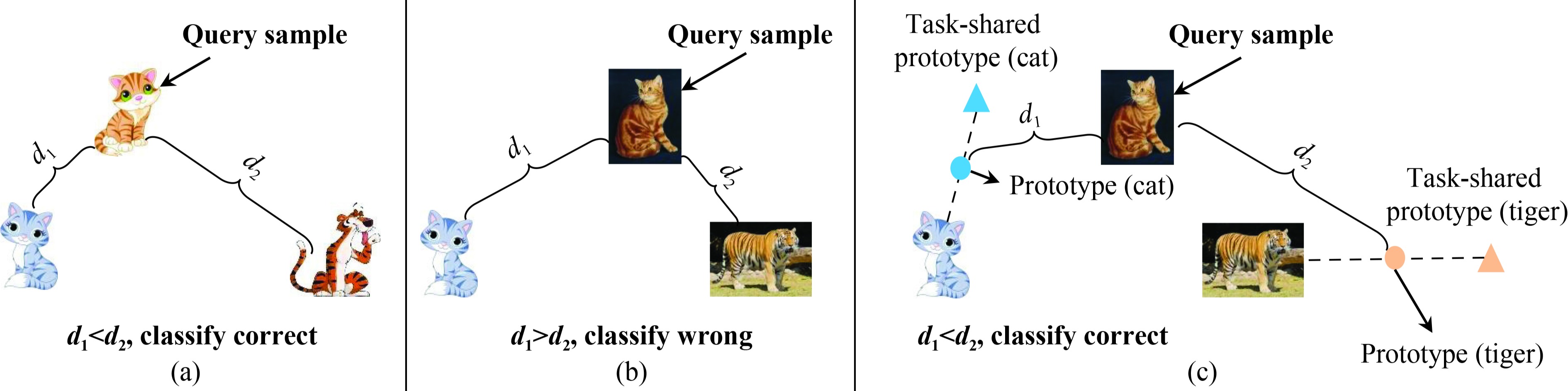
Combat data shift in few-shot learning with knowledge graph
Yongchun ZHU, Fuzhen ZHUANG, Xiangliang ZHANG, Zhiyuan QI, Zhiping SHI, Juan CAO, Qing HE.
doi:10.1007/s11704-022-1339-7
2023, 17(1): 171305
摘要
Many few-shot learning approaches have been designed under the meta-learning framework, which learns from a variety of learning tasks and generalizes to new tasks. These meta-learning approaches achieve the expected performance in the scenario where all samples are drawn from the same distributions (i.i.d. observations). However, in real-world applications, few-shot learning paradigm often suffers from data shift, i.e., samples in different tasks, even in the same task, could be drawn from various data distributions. Most existing few-shot learning approaches are not designed with the consideration of data shift, and thus show downgraded performance when data distribution shifts. However, it is non-trivial to address the data shift problem in few-shot learning, due to the limited number of labeled samples in each task.
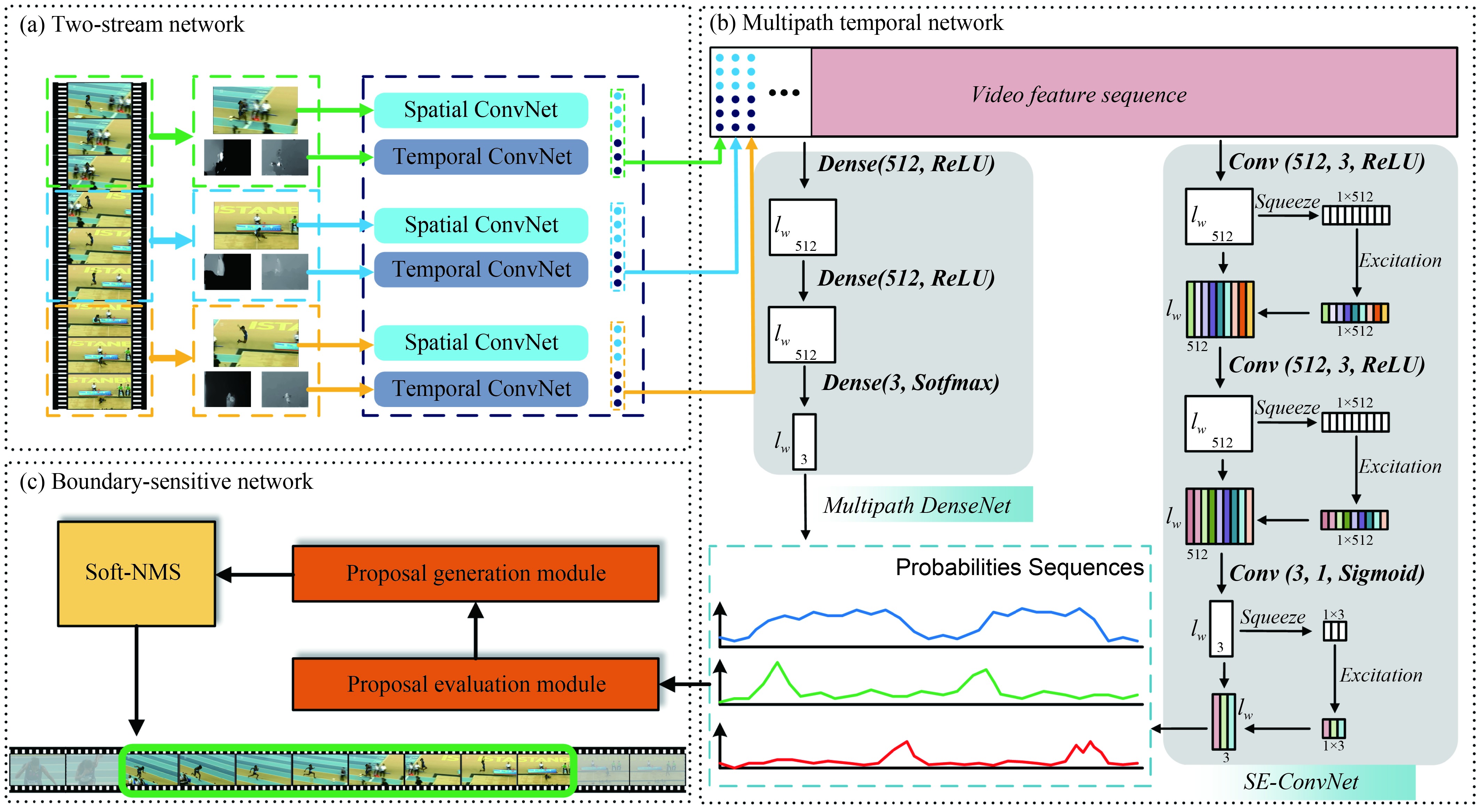
Accelerating temporal action proposal generation via high performance computi...
Tian WANG, Shiye LEI, Youyou JIANG, Choi CHANG, Hichem SNOUSSI, Guangcun SHAN, Yao FU.
doi:10.1007/s11704-021-0173-7
2022, 16(4): 164317
摘要
Temporal action proposal generation aims to output the starting and ending times of each potential action for long videos and often suffers from high computation cost. To address the issue, we propose a new temporal convolution network called Multipath Temporal ConvNet (MTCN). In our work, one novel high performance ring parallel architecture based is further introduced into temporal action proposal generation in order to respond to the requirements of large memory occupation and a large number of videos. Remarkably, the total data transmission is reduced by adding a connection between multiplecomputing load in the newly developed architecture. Compared to the traditional Parameter Server architecture, our parallel architecture has higher efficiency on temporal action detection tasks with multiple GPUs. We conduct experiments on ActivityNet-1.3 and THUMOS14, where our method outperformsother state-of-art temporal action detection methods with high recall and high temporal precision.
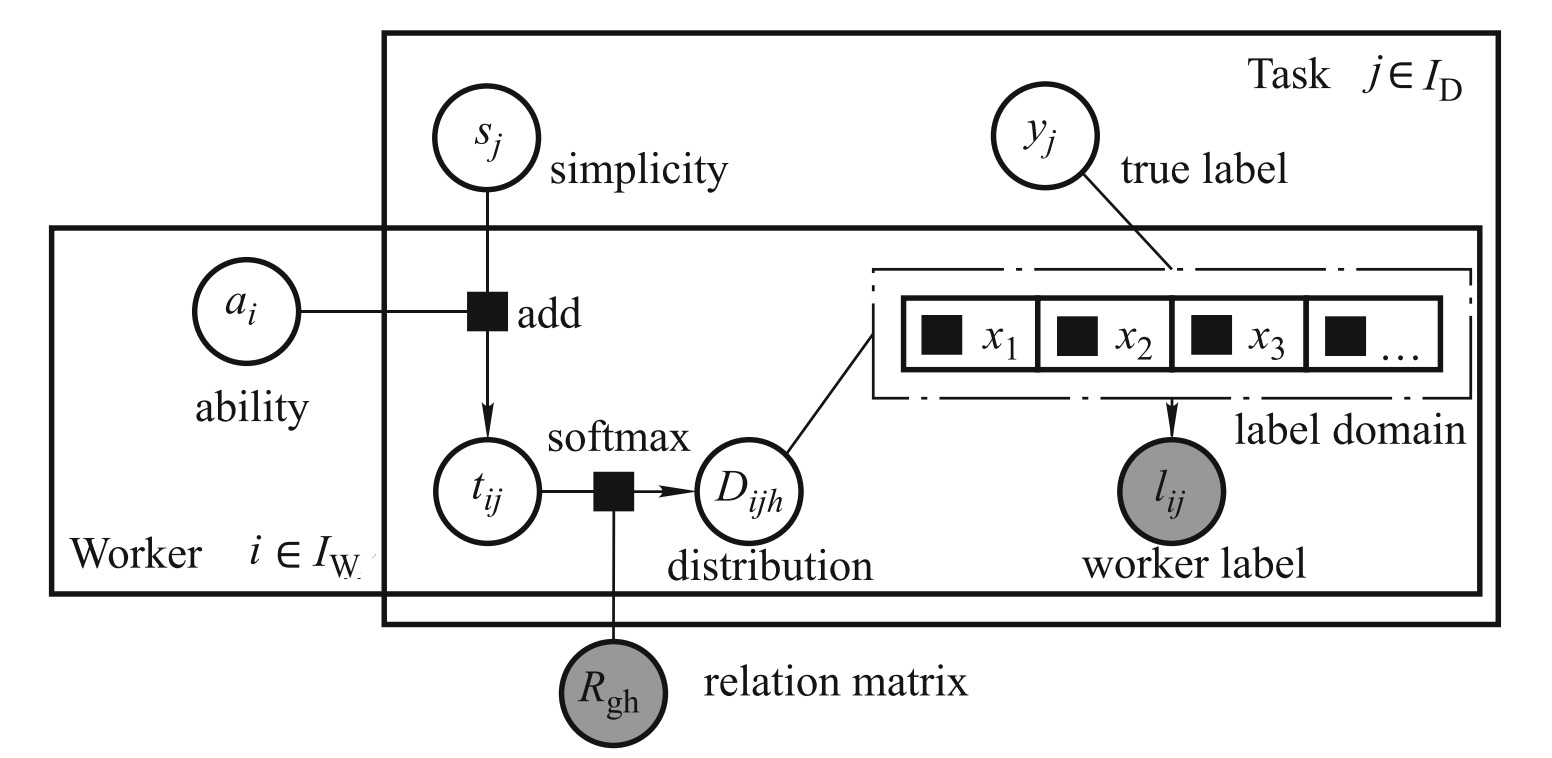
Find truth in the hands of the few: acquiring specific knowledge with crowdso...
Tao HAN, Hailong SUN, Yangqiu SONG, Yili FANG, Xudong LIU.
doi:doi.org/10.1007/s11704-020-9364-x
2021, 15(4): 154315
摘要
Crowdsourcing has been a helpful mechanism to leverage human intelligence to acquire useful knowledge.However, when we aggregate the crowd knowledge based on the currently developed voting algorithms, it often results in common knowledge that may not be expected. In this paper, we consider the problem of collecting specific knowledge via crowdsourcing. With the help of using external knowledge base such as WordNet, we incorporate the semantic relations between the alternative answers into a probabilisticmodel to determine which answer is more specific. We formulate the probabilistic model considering both worker’s ability and task’s difficulty from the basic assumption, and solve it by the expectation-maximization (EM) algorithm. To increase algorithm compatibility, we also refine our method into semi-supervised one.

Big graph search: challenges and techniques
Shuai MA, Jia LI, Chunming HU, Xuelian LIN, Jinpeng HUAI.
doi:10.1007/s11704-015-4515-1
摘要
On one hand, compared with traditional relational and XML models, graphs have more expressive power and are widely used today. On the other hand, various applications of social computing trigger the pressing need of a new search paradigm. In this article, we argue that big graph search is the one filling this gap. We first introduce the application of graph search in various scenarios. We then formalize the graph search problem, and give an analysis of graph search from an evolutionary point of view, followed by the evidences from both the industry and academia. After that, we analyze the difficulties and challenges of big graph search. Finally, we present three classes of techniques towards big graph search: query techniques, data techniques and distributed computing techniques.
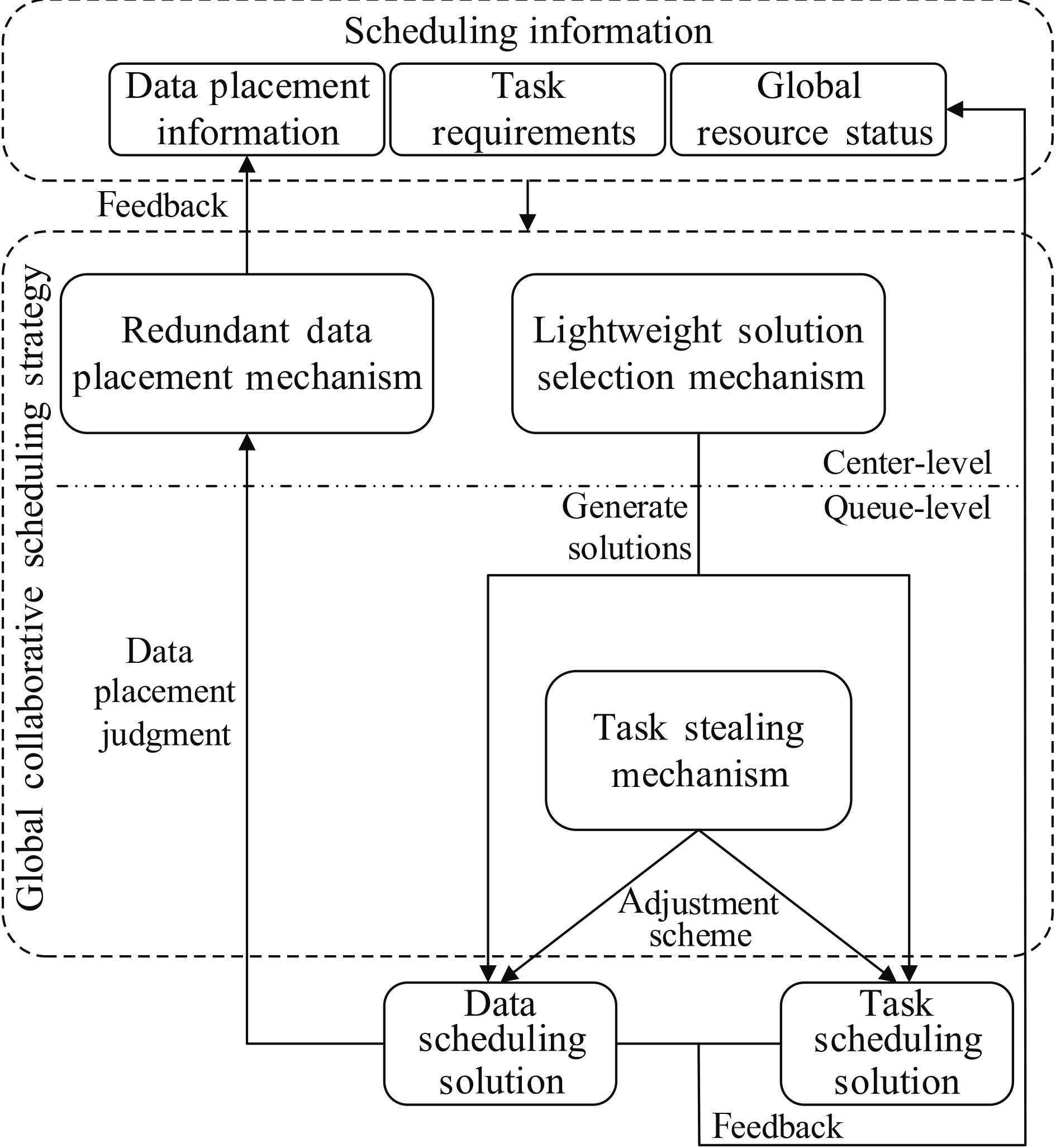
GCSS: a global collaborative scheduling strategy for wide-area high-performan...
Yao SONG, Limin XIAO, Liang WANG, Guangjun QIN, Bing WEI, Baicheng YAN, Chenhao ZHANG.
doi:10.1007/s11704-021-0353-5
2022, 16(5): 165105
摘要
Wide-area high-performance computing is widely used for large-scale parallel computing applications owing to its high computing and storage resources. However, the geographical distribution of computing and storage resources makes efficient task distribution and data placement more challenging. To achieve a higher system performance, this study proposes a two-level global collaborative scheduling strategy for wide-area high-performance computing environments. The collaborative scheduling strategy integrates lightweight solution selection, redundant data placement and task stealing mechanisms, optimizing task distribution and data placement to achieve efficient computing in wide-area environments. The experimental results indicate that compared with the state-of-the-art collaborative scheduling algorithm HPS+
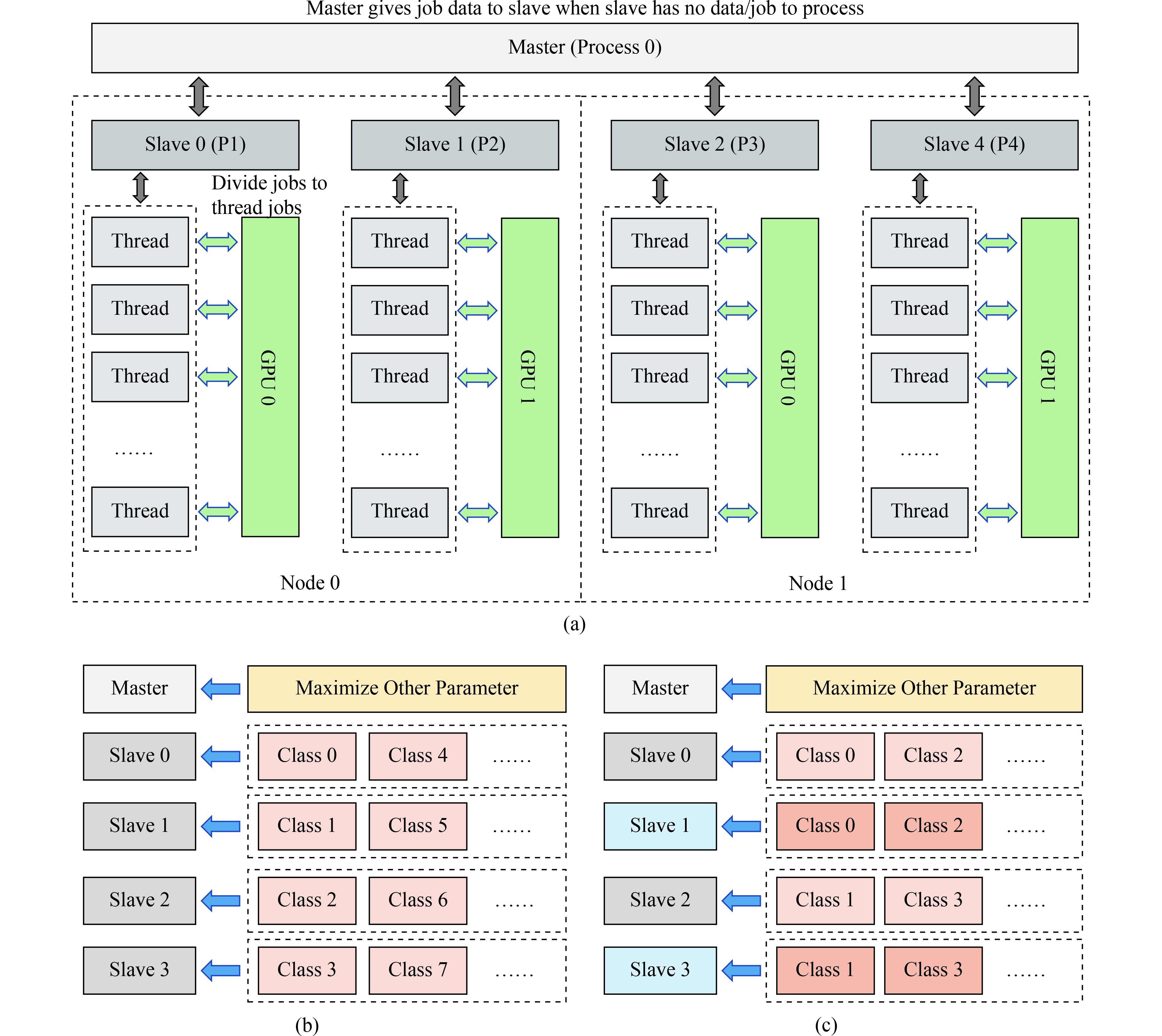
Accelerating the cryo-EM structure determination in RELION on GPU cluster
Xin YOU, Hailong YANG, Zhongzhi LUAN, Depei QIAN.
doi:10.1007/s11704-020-0169-8
2022, 16(3): 163102
摘要
The cryo-electron microscopy (cryo-EM) is one of the most powerful technologies available today for structural biology. The RELION (Regularized Likelihood Optimization) implements a Bayesian algorithm for cryo-EM structure determination, which is one of the most widely used software in this field. Many researchers have devoted effort to improve the performance of RELION to satisfy the analysis for the ever-increasing volume of datasets. In this paper, we focus on performance analysis of the most time-consuming computation steps in RELION and identify their performance bottlenecks for specific optimizations. We propose several performance optimization strategies to improve the overall performance of RELION, including optimization of expectation step, parallelization of maximization step, accelerating the computation of symmetries, and memory affinity optimization.
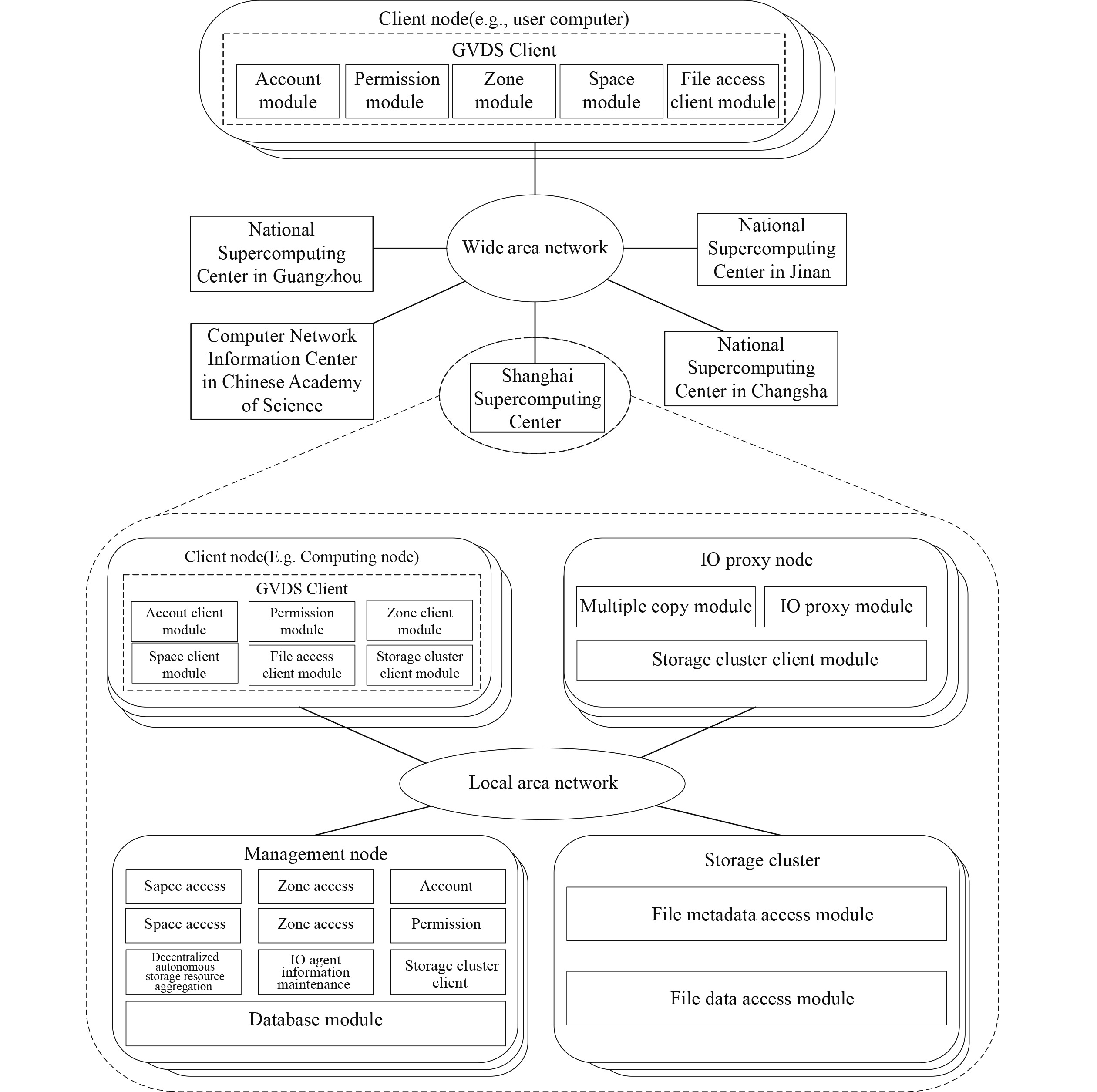
Research on key technologies of edge cache in virtual data space across WAN
Jiantong HUO, Yaowen XU, Zhisheng HUO, Limin XIAO, Zhenxue HE.
doi:10.1007/s11704-022-1176-8
2023, 17(1): 171102
摘要
The authors of this paper have previously proposed the global virtual data space system (GVDS) to aggregate the scattered and autonomous storage resources in China’s national supercomputer grid (National Supercomputing Center in Guangzhou, National Supercomputing Center in Jinan, National Supercomputing Center in Changsha, Shanghai Supercomputing Center, and Computer Network Information Center in Chinese Academy of Sciences) into a storage system that spans the wide area network (WAN), which realizes the unified management of global storage resources in China. At present, the GVDS has been successfully deployed in the China National Grid environment. However, when accessing and sharing remote data in the WAN, the GVDS will cause redundant transmission of data and waste a lot of network bandwidth resources. In this paper, we propose an edge cache system as a supplementary system of the GVDS to improve the performance of upper-level applications accessing and sharing remote data.
-
1
The role of mechanoreceptors in acupuncture
Medicine in Novel Technology and Devices2023,21(3)
-
2
MV-mediated biomineralization mechanisms and treatments of biomineralized dis...
Medicine in Novel Technology and Devices2023,21(3)
-
3
SR-AFU: super-resolution network using adaptive frequency component upsamplin...
Frontiers of Computer Science2023,21(3)
-
4
Unsupervised statistical text simplification using pre-trained language model...
Frontiers of Computer Science2023,21(3)
-
5
推力矢量型V/STOL飞行器动态过渡过程的操纵策略优化
航空动力学报2023,21(3)
-
6
耦合传热下激波对超声速气膜冷却影响
航空动力学报2023,21(3)
-
北京航空航天大学学报
-
北京航空航天大学学报(社会科学版)
-
复合材料学报
-
集成电路与嵌入式系统
-
航空学报
-
Chinese Journal of Aeronautics
-
航空动力学报
-
Frontiers of Computer Science
-
Propulsion and Power Research
-
Medicine in Novel Technology and Devices
-
Digital Twin
-
Electromagnetics Science and Technology
-
Congnitive Semantics
-
The Journal of the Air Transport Research Society
-
航空知识
-
问天少年
-
Chain
-
Virtual Reality & Intelligent Hardware
-
International Journal of Modeling Simulation and Scientific Computing
-
International Journal of Service and Computing Oriented Manufacturing
-
Mathematics in computer science
-
Atlantis Highlights in Engineering
-
Mathematical Blosciences and Engineering
-
Materials LAB
-
Journal of Economy and Technology
-
Digital Engineering
-
Guidance Navication and Control
-
Visual Computing for Industry Biomedicine and Art
-
图学学报